


ალგორითმული მიკერძოება: მონაცემთა ასიმეტრია, ოპტიმიზაცია და ნეიტრალობის ილუზია
 Tornike Moss
Tornike Moss

განახლდა • 14-03-2026, 13:28 • კორექტირება
თანამედროვე ტექნოლოგიურ ეპოქაში ხელოვნური ინტელექტის სისტემები წარმოადგენს არა მხოლოდ გამოთვლით ინსტრუმენტებს, არამედ რთულ სოციალურ-ტექნიკურ კონსტრუქტებს, რომლებიც აქტიურად აყალიბებენ ადამიანური ყოფის ასპექტებს. ამ ტრანსფორმაციული პროცესის ეპიცენტრში დგას ალგორითმული მიკერძოების ფენომენი, რომელიც ხშირად არასწორად არის გაგებული, როგორც უბრალო პროგრამული ხარვეზი. სინამდვილეში, ალგორითმული მიკერძოება არ არის მხოლოდ ტექნიკური დეფექტი; იგი ბუნებრივად აღმოცენდება მონაცემთა განაწილების ასიმეტრიიდან, მანქანური სწავლების მოდელების ოპტიმიზაციის მიზნებიდან და იმ ფართო სოციალურ-ტექნიკური კონტექსტიდან, რომელშიც ეს მოდელები ფუნქციონირებენ. საზოგადოებაში ღრმად არის გამჯდარი ნეიტრალობის ილუზია — რწმენა იმისა, რომ მათემატიკური ფორმულები და სტატისტიკური მოდელები თავისუფალია ადამიანური სუბიექტურობისგან. თუმცა, ეს პერსპექტივა უგულებელყოფს იმ ფაქტს, რომ ალგორითმი არის მხოლოდ ინდუქციური მექანიზმი, რომელიც ექსტრაპოლაციას უკეთებს წარსულში არსებულ პატერნებს მომავლის პროგნოზირებისთვის.
შესაბამისად, ნებისმიერი ალგორითმული სისტემა არის იმ ისტორიული მონაცემების მათემატიკური ანარეკლი, რომელზეც ის დატრენინგდა. ხელოვნური ინტელექტის ეთიკის განხილვისას აუცილებელია ჩავუღრმავდეთ იმ ფუნდამენტურ მექანიზმებს, რომლებიც განაპირობებენ მოდელის ქცევას. ალგორითმული გადაწყვეტილების მიღების პროცესი ეფუძნება ალბათურ ლოგიკასა და სტატისტიკურ დასკვნებს, სადაც გამომავალი შედეგი წარმოადგენს შემავალი ცვლადების კომპლექსური ურთიერთქმედების პროდუქტს. ამ პროცესში მიკერძოება ინტეგრირდება არა ავტორის შეგნებული განზრახვით, არამედ სისტემის არქიტექტურული და სტატისტიკური თვისებების გამო. მონაცემთა შეგროვების მეთოდოლოგია და მოდელის შეფასების მეტრიკები ერთობლივად ქმნიან გარემოს, სადაც სისტემატური გადახრები გარდაუვალი ხდება.
ხელოვნური ინტელექტის ეპისტემოლოგიური ბუნება რადიკალურად განსხვავდება კლასიკური პროგრამირებისგან. ტრადიციულ სისტემებში წესებს განსაზღვრავს ადამიანი, ხოლო მანქანური სწავლების პარადიგმაში მოდელი თავად გამოიტანს კანონზომიერებებს ემპირიული დაკვირვებებიდან. სწორედ ეს ინდუქციური ნახტომი წარმოადგენს იმ კრიტიკულ წერტილს, სადაც ობიექტურობის ილუზია იმსხვრევა. ალგორითმი ვერ განასხვავებს კორელაციასა და კაუზალობას; მისთვის ნებისმიერი სტატისტიკურად მყარი კავშირი წარმოადგენს ვალიდურ სიგნალს. როდესაც ვამტკიცებთ, რომ ალგორითმული მიკერძოება სოციალურ-ტექნიკური ფენომენია, ვგულისხმობთ იმას, რომ საზოგადოებრივი სტრუქტურები და ისტორიული უთანასწორობები კოდირდება მონაცემებში და შემდგომ ლეგიტიმირდება ალგორითმული ავტორიტეტის მეშვეობით. ამ მრავალნაწილიანი ანალიტიკური სერიის პირველ ფაზაში ჩვენ ფოკუსირებას მოვახდენთ იმ ტექნიკურ და მეთოდოლოგიურ საფუძვლებზე, რომლებიც წარმოშობენ მიკერძოებას, და დეტალურად განვიხილავთ, თუ როგორ გარდაიქმნება მონაცემთა ასიმეტრია და ოპტიმიზაციის პროცესები სისტემატიურ გადახრებად.
სწრაფი შეჯამება
- ალგორითმული მიკერძოება არ არის უბრალოდ პროგრამული შეცდომა; ის ხშირად წარმოიქმნება მონაცემთა ასიმეტრიული განაწილებისგან და მანქანური სწავლების ოპტიმიზაციის პროცესებისგან.
- მანქანური სწავლების მოდელები სწავლობენ ისტორიულ მონაცემებზე, რის გამოც სოციალური უთანასწორობები და სტრუქტურული დისბალანსები შეიძლება პირდაპირ აისახოს ალგორითმულ გადაწყვეტილებებში.
- შერჩევის მიკერძოება, მონიშვნის დისტორცია და უკუკავშირის მარყუჟები ქმნის თვითგანმტკიცებად პროცესებს, სადაც ალგორითმის პროგნოზები თავად იწყებენ მონაცემთა მომავალ ფორმირებას.
- სამართლიანობის მათემატიკური მეტრიკები ცდილობს მიკერძოების გაზომვას, თუმცა სხვადასხვა მეტრიკას შორის ხშირად არსებობს ფუნდამენტური კომპრომისი, რომელიც ერთდროულ სრულ დაკმაყოფილებას შეუძლებელს ხდის.
- მიკერძოების შერბილება შესაძლებელია მონაცემთა წინასწარი დამუშავებით, ტრენინგის პროცესში ჩარევით ან შედეგების კორექტირებით, თუმცა თითოეული მეთოდი მოითხოვს სიზუსტესა და სამართლიანობას შორის კომპრომისს.
- ალგორითმები ვერ იქნებიან სრულად ნეიტრალური, რადგან ისინი ასახავენ იმ მონაცემებს, ინსტიტუციურ პრიორიტეტებს და სოციალურ კონტექსტს, რომელშიც ისინი იქმნება და გამოიყენება.
შინაარსი
- ალგორითმული მიკერძოების ტექნიკური საფუძველი: მონაცემთა განაწილება და ოპტიმიზაციის ფუნქცია
- შერჩევის მიკერძოება, მონიშვნის დისტორცია და უკუკავშირის მარყუჟები
- სამართლიანობის მათემატიკური მეტრიკები და მათი შეზღუდვები
- მიკერძოების შერბილების სტრატეგიები: წინასწარი, შიდა და შემდგომი ჩარევა
- რატომ ვერ იქნება ალგორითმი სრულად ნეიტრალური?
- სისტემური შეჯამება
ალგორითმული მიკერძოების ტექნიკური საფუძველი: მონაცემთა განაწილება და ოპტიმიზაციის ფუნქცია
მანქანური სწავლების მოდელის ფუნდამენტური მიზანია შეისწავლოს ფუნქცია, რომელიც მაქსიმალური სიზუსტით ასახავს კავშირს შემავალ ცვლადებსა და სასურველ გამომავალ შედეგს შორის. ამ პროცესის გასააზრებლად აუცილებელია მიკერძოების, როგორც სტატისტიკური კონცეფციის, გამიჯვნა მისი ფართო სოციოლოგიური გაგებისგან. სტატისტიკაში მიკერძოება გულისხმობს სისტემატურ განსხვავებას მოდელის მიერ პროგნოზირებულ მნიშვნელობებსა და რეალურ მნიშვნელობებს შორის. მანქანური სწავლების კონტექსტში, მაღალი მიკერძოება მიუთითებს მოდელის უუნარობაზე, დააფიქსიროს კომპლექსური მიმართებები. თუმცა, როდესაც ხელოვნური ინტელექტის ეთიკის ჭრილში ვსაუბრობთ ალგორითმულ მიკერძოებაზე, ჩვენ ვეხებით მის მიერ გენერირებული შედეგების სისტემატურ და არაპროპორციულ გავლენას სხვადასხვა სოციალურ ჯგუფზე.
ეს სისტემატური გადახრა პირდაპირ კავშირშია მონაცემთა განაწილებასთან. ნებისმიერი მოდელი ტრენინგდება კონკრეტულ მონაცემთა სიმრავლეზე, რომელიც წარმოადგენს მრავალგანზომილებიან სივრცეში არსებულ სტატისტიკურ განაწილებას. თუ ეს განაწილება ასიმეტრიულია — ანუ გარკვეული კლასები ჭარბად არის წარმოდგენილი, ხოლო სხვები დეფიციტურად — მოდელის სწავლების პროცესი ამ ასიმეტრიას თავის შიდა პარამეტრებში ასახავს. ტრენინგის პროცესი არსებითად არის ემპირიული რისკის მინიმიზაციის მექანიზმი. მოდელის არქიტექტურა იყენებს ობიექტურ ფუნქციას, რომელიც განსაზღვრავს მიზანს, და დანაკარგის ფუნქციას, რომელიც ზომავს შეცდომის სიდიდეს. გრადიენტული დაშვების მსგავსი ალგორითმები მუდმივად ანახლებენ მოდელის წონებს ისე, რომ მინიმუმამდე დაიყვანონ ჯამური დანაკარგი მთლიან სატრენინგო სიმრავლეზე.
სწორედ აქ იკვეთება კრიტიკული დისონანსი ოპტიმიზაციასა და სამართლიანობას შორის. დანაკარგის ფუნქციის მინიმიზაცია გულისხმობს გლობალური საშუალო შეცდომის შემცირებას. როდესაც სატრენინგო მონაცემებში დომინირებს უმრავლესობის კლასი, მოდელისთვის მათემატიკურად ყველაზე რაციონალურია ამ კლასის პატერნების სრულყოფილად ათვისება, რადგან სწორედ ეს უზრუნველყოფს ჯამური დანაკარგის ყველაზე სწრაფ შემცირებას. უმცირესობის კლასებზე დაშვებული შეცდომები მცირე გავლენას ახდენს საერთო გრადიენტზე, შესაბამისად, ალგორითმი ავლენს ტენდენციას, უგულებელყოს იშვიათი შემთხვევები.
ოპტიმიზაცია არ უდრის სამართლიანობას, რადგან მათემატიკური ოპტიმიზაციის ალგორითმი მოკლებულია ყოველგვარ კონტექსტუალურ გაგებას თანასწორობის შესახებ. მისთვის ნებისმიერი მონაცემი მხოლოდ ვექტორია, ხოლო მიზანი — სკალარული მნიშვნელობის მინიმიზაცია.
ოპტიმიზაციის ეს მათემატიკური სიბრმავე განსაკუთრებით კრიტიკულია მაშინ, როდესაც საქმე გვაქვს მრავალგანზომილებიან მონაცემებთან, სადაც კორელაციები ხშირად ფარულია. ალგორითმი პოულობს უმოკლეს გზას შეცდომის მინიმიზაციისკენ, თუნდაც ეს გზა გადიოდეს სოციალურად სენსიტიური მახასიათებლების, როგორიცაა რასა, გენდერი ან ეკონომიკური სტატუსი, არაპირდაპირ გამოყენებაზე. ტექნიკურ ენაზე ამას პროქსი-ცვლადების მეშვეობით დისკრიმინაცია ეწოდება, სადაც მოდელი ოფიციალურად არ იყენებს აკრძალულ ატრიბუტს, მაგრამ ეყრდნობა სხვა ცვლადებს, რომლებიც სტატისტიკურად მჭიდროდ არიან დაკავშირებული ამ ატრიბუტთან.
შესაბამისად, მაღალი გლობალური სიზუსტის მქონე მოდელი შესაძლოა მკვეთრად მიკერძოებული იყოს კონკრეტული სუბ-პოპულაციებისთვის. მაგალითად, თუ მოდელი დატრენინგებულია მონაცემებზე, სადაც ოთხმოცდაათი პროცენტი ერთ დემოგრაფიულ ჯგუფს ეკუთვნის, მოდელმა შეიძლება მიაღწიოს მაღალ სიზუსტეს მხოლოდ იმით, რომ სრული იგნორირება გაუკეთოს დანარჩენ ათ პროცენტს. ტექნიკური თვალსაზრისით, ეს არის წარმატებული ოპტიმიზაციის პროცესი, რადგან დანაკარგის ფუნქციამ მიაღწია მინიმუმს. თუმცა, სოციალურ-ტექნიკური პერსპექტივით, ეს არის სტრუქტურული დისფუნქცია. მოდელის წონები, რომლებიც ინახავენ დასწავლილ ინფორმაციას, ხდებიან მონაცემთა დისბალანსის მათემატიკური კრისტალიზაციები. ოპტიმიზაციის პარადიგმა ორიენტირებულია უმრავლესობის პრეფერენციების დაკმაყოფილებაზე, რაც სტრუქტურულად გამორიცხავს თანაბარი რეპრეზენტაციის შესაძლებლობას დამატებითი ჩარევების გარეშე.
განვიხილოთ ჯვარედინი ენტროპიის ან საშუალო კვადრატული ცდომილების მაგალითები. ეს ფუნქციები აგრეგირებულად აფასებენ მოდელის პერფორმანსს. როდესაც მონაცემთა სივრცეში არსებობს მკვეთრი ასიმეტრია, მოდელის პარამეტრების განახლების ვექტორი ძირითადად განისაზღვრება დომინანტური ჯგუფის მახასიათებლებით. იშვიათი შემთხვევები აღიქმება როგორც სტატისტიკური ხმაური ან ანომალიები. მოდელის გენერალიზაციის უნარი, რომელიც მიზნად ისახავს ზედმეტი მორგების თავიდან აცილებას, პარადოქსულად იწვევს უმცირესობების სპეციფიკური მახასიათებლების წაშლას. შედეგად ვიღებთ სისტემას, რომელიც ტექნიკურად ოპტიმიზებულია, მაგრამ კონტექსტუალურად პრობლემურია, რადგან ის აწესებს სტანდარტს, რომელიც მხოლოდ მონაცემთა უმრავლესობისთვისაა რელევანტური.
შერჩევის მიკერძოება, მონიშვნის დისტორცია და უკუკავშირის მარყუჟები
მანქანური სწავლების მოდელების ტექნიკური ოპტიმიზაციის მიღმა, ალგორითმული მიკერძოების ფესვები უშუალოდ მონაცემთა გენერირებისა და შეგროვების პროცესებში მდებარეობს. ამ პროცესში ერთ-ერთი ყველაზე კრიტიკული პრობლემაა შერჩევის მიკერძოება (sampling bias), რომელიც წარმოიქმნება მაშინ, როდესაც სატრენინგო მონაცემთა სიმრავლე არ წარმოადგენს იმ რეალური პოპულაციის რანდომიზებულ და რეპრეზენტაციულ ასლს, რომელზეც მოდელი უნდა დაინერგოს. სტატისტიკურ კონტექსტში, თუ მონაცემთა შერჩევის პროცესი არ არის დამოუკიდებელი და ერთნაირად განაწილებული, მოდელის მიერ გაკეთებული სტატისტიკური დასკვნები კარგავენ ვალიდურობას. რეპრეზენტაციული დისბალანსი ნიშნავს, რომ გარკვეული ჯგუფების გამოცდილება სისტემატურად არის გამოტოვებული მონაცემთა ბაზიდან. როდესაც მოდელი ტრენინგდება ასეთ ნაკლოვან სივრცეზე, მისთვის ის, რაც არ არსებობს მონაცემებში, არ არსებობს რეალობაშიც. ეს იწვევს ეპისტემოლოგიურ სიბრმავეს, სადაც სისტემა უუნარო ხდება ამოიცნოს იმ ჯგუფების შემავალი სიგნალები, რომლებიც სატრენინგო ფაზაში მარგინალიზებულნი იყვნენ.
შერჩევის პრობლემასთან ერთად, არანაკლებ კრიტიკულია მონიშვნის მიკერძოება, რომელიც უშუალოდ ზედამხედველობითი სწავლების პარადიგმის სტრუქტურული მახასიათებელია. ზედამხედველობითი სწავლებისას ალგორითმი მოითხოვს ჭეშმარიტების ფუძეს, ანუ წინასწარ მონიშნულ მონაცემებს. თუმცა, ეს მონიშვნები იშვიათად წარმოადგენენ ობიექტურ ჭეშმარიტებას; ისინი ადამიანური გადაწყვეტილებების ან ისტორიული პროცესების პროდუქტია. მონიშვნის დისტორსია ხდება მაშინ, როდესაც ჩვენ ვცდილობთ ალგორითმულად ვიწინასწარმეტყველოთ აბსტრაქტული კონცეფცია და მის ნაცვლად ვიყენებთ ხელშესახებ, მაგრამ მიკერძოებულ პროქსი ცვლადს. მაგალითად, თუ ალგორითმის მიზანია დანაშაულის ალბათობის პრედიქცია, რეალურად მონაცემთა ბაზაში მონიშნულია არა თავად დანაშაულის აქტი, არამედ დაპატიმრების ფაქტი. დაპატიმრება კი არ არის დანაშაულის ობიექტური საზომი; ის ასახავს პოლიციის პატრულირების სიხშირეს და ისტორიულად ჩამოყალიბებულ პრაქტიკებს, რომლებიც შესაძლოა თავად შეიცავდეს სტრუქტურულ ასიმეტრიებს. როდესაც მოდელი სწავლობს ამ გამრუდებულ მონიშვნებზე, ის ფაქტობრივად ახდენს სტრუქტურული მიკერძოებების იმიტაციას.

მონიშვნის მიკერძოების კიდევ ერთი თვალსაჩინო მაგალითია დასაქმების ალგორითმები. თუ კომპანია ისტორიულად ძირითადად ერთ კონკრეტულ დემოგრაფიულ ჯგუფს ასაქმებდა და აწინაურებდა, წარმატებული თანამშრომლის ჭეშმარიტების ფუძე სწორედ ამ ჯგუფის მახასიათებლებით იქნება გაჯერებული. ალგორითმი, რომელიც სწავლობს ამ ისტორიულ რეზიუმეებზე, ავტომატურად დაბალ შეფასებას მისცემს განსხვავებული პროფილის მქონე კანდიდატებს, არა იმიტომ, რომ ისინი ნაკლებად კვალიფიციურები არიან, არამედ იმიტომ, რომ მათი მონაცემები არ ემთხვევა ისტორიულად წარმატებულად მონიშნულ პატერნს.
ეს სტრუქტურული დეფექტები კიდევ უფრო რთულდება უკუკავშირის მარყუჟების მეშვეობით. მანქანური სწავლების სისტემები არ ფუნქციონირებენ იზოლირებულ ვაკუუმში; ისინი წარმოადგენენ დინამიკური სისტემების ნაწილს, სადაც მოდელის მიერ გენერირებული პროგნოზები აქტიურად ცვლიან იმ გარემოს, რომელშიც ისინი მოქმედებენ. უკუკავშირის მარყუჟი (feedback loop) არის თვითგანმტკიცებადი მექანიზმი, სადაც ალგორითმის გამომავალი შედეგი გავლენას ახდენს მომავალი მონაცემების გენერირების პროცესზე, რომელიც შემდგომ ისევ ამავე ალგორითმის სატრენინგო ბაზად გამოიყენება. ეს ქმნის დახურულ წრეს, სადაც თავდაპირველი მიკერძოება დროთა განმავლობაში ექსპონენციალურად იზრდება.
განვიხილოთ პრედიქციული პოლიციური სისტემების ან სარეკომენდაციო ალგორითმების მაგალითი. თუ მოდელი დაასკვნის, რომ გარკვეული გეოგრაფიული არეალი მაღალი რისკის მატარებელია, ამ არეალში გაიგზავნება მეტი რესურსი. გაზრდილი კონცენტრაცია ბუნებრივად გამოიწვევს მეტი დარღვევის დაფიქსირებას, რაც სისტემაში შევა როგორც ახალი მონაცემი. მოდელი ამ ახალ მონაცემებს აღიქვამს როგორც საკუთარი პროგნოზის სისწორის უტყუარ მტკიცებულებას. იგივე პრინციპი მოქმედებს ინფორმაციულ ეკოსისტემებში: სარეკომენდაციო სისტემა მომხმარებელს სთავაზობს კონტენტს მისი წარსული ქცევის საფუძველზე, მომხმარებელი მოიხმარს ამ კონტენტს, რაც თავის მხრივ ამყარებს ალგორითმის პარამეტრებს. უკუკავშირის მარყუჟები შლიან ზღვარს პროგნოზსა და რეალობის კონსტრუირებას შორის. მოდელი ხდება რეალობის აქტიური ფორმირების ინსტრუმენტი, რომელიც საკუთარ მიკერძოებულ პროგნოზებს თვითაღსრულებად წინასწარმეტყველებებად გარდაქმნის. ამ დინამიკურ პროცესში, ალგორითმული სისტემა კარგავს უნარს, ობიექტურად შეასწოროს საკუთარი შეცდომები, რადგან ყოველი ახალი მონაცემი არის არა დამოუკიდებელი ემპირიული ფაქტი, არამედ მისივე წინა გადაწყვეტილებებით გენერირებული არტეფაქტი. მონაცემთა ეს ციკლური ბუნება უზრუნველყოფს იმას, რომ საწყისი ასიმეტრია გარდაიქმნება მუდმივ სტატისტიკურ რეალობად.
სამართლიანობის მათემატიკური მეტრიკები და მათი შეზღუდვები
ალგორითმული სისტემების სამართლიანობის შეფასების მცდელობამ განაპირობა მრავალფეროვანი მათემატიკური მეტრიკების (fairness metrics) შემუშავება, რომლებიც მიზნად ისახავენ მიკერძოების კვანტიფიკაციას. თუმცა, ამ პროცესმა გამოავლინა ფუნდამენტური ეპისტემოლოგიური პრობლემა: სამართლიანობა არ არის უნივერსალური, მონოლითური კონცეფცია, რომელიც ექვემდებარება ერთმნიშვნელოვან მათემატიკურ ფორმალიზაციას. ინდუსტრიასა და აკადემიურ სივრცეში ფართოდ გამოიყენება რამდენიმე ძირითადი საზომი, რომელთაგან თითოეული სამართლიანობის განსხვავებულ ფილოსოფიურ პრინციპს ეფუძნება. დემოგრაფიული პარიტეტი მოითხოვს, რომ პოზიტიური გადაწყვეტილების მიღების სიხშირე იდენტური იყოს ყველა სოციალური თუ დემოგრაფიული ჯგუფისთვის, მიუხედავად იმისა, თუ როგორია ამ ჯგუფებში სამიზნე ცვლადის საბაზისო განაწილება. ეს მიდგომა ორიენტირებულია ისტორიული უთანასწორობის კომპენსირებაზე, მაგრამ ხშირად აწყდება წინააღმდეგობას ალგორითმის პრედიქციულ სიზუსტესთან, რადგან იგნორირებას უკეთებს ჯგუფებს შორის არსებულ რეალურ სტატისტიკურ განსხვავებებს.
მეორე მხრივ, გათანაბრებული შანსების მეტრიკა ფოკუსირდება არა უშუალოდ შედეგების თანაბარ განაწილებაზე, არამედ შეცდომის კოეფიციენტების სიმეტირულობაზე. ამ სტანდარტის მიხედვით, ალგორითმი სამართლიანია მაშინ, როდესაც ჭეშმარიტად პოზიტიური და ცრუ პოზიტიური მაჩვენებლები იდენტურია ყველა დაცული ჯგუფისთვის. ეს ნიშნავს, რომ მოდელი თანაბარი სიზუსტით უნდა ემსახურებოდეს სხვადასხვა პოპულაციას და არ უნდა უშვებდეს დისპროპორციულად მეტ შეცდომას რომელიმე კონკრეტული უმცირესობის მიმართ. ამასთანავე, არსებობს პრედიქციული პარიტეტისა და კალიბრაციის კონცეფცია, რომელიც მოითხოვს, რომ მოდელის მიერ მინიჭებული ალბათობები ობიექტურად ასახავდეს რეალურ შანსებს ყველა ჯგუფისთვის. თუ ალგორითმი აფასებს მოვლენის დადგომის ალბათობას სამოცდაათი პროცენტით, რეალობაში ეს მოვლენა შემთხვევათა სამოცდაათ პროცენტში უნდა ხდებოდეს, განურჩევლად ობიექტის დემოგრაფიული კატეგორიისა.
მიუხედავად თითოეული მეტრიკის ლოგიკური ვალიდურობისა, მანქანური სწავლების თეორიაში არსებობს მკაცრი მათემატიკური შეზღუდვები, რომლებიც შეუძლებელს ხდის მათ ერთდროულ დაკმაყოფილებას. კლაინბერგის, მულაინათანისა და რაღავანის მიერ ფორმულირებული შეუძლებლობის თეორემები ნათლად აჩვენებს, რომ თუ სხვადასხვა ჯგუფს აქვს სამიზნე ცვლადის განსხვავებული საბაზისო მაჩვენებელი, მათემატიკურად გამორიცხულია გათანაბრებული შანსებისა და პრედიქციული კალიბრაციის ერთდროულად მიღწევა. გამონაკლისს წარმოადგენს მხოლოდ ის ჰიპოთეტური სცენარი, სადაც მოდელის პრედიქციული სიზუსტე აბსოლუტურია. ეს შეუძლებლობის შედეგები ადასტურებს, რომ სამართლიანობის მეტრიკებს შორის არჩევანის გაკეთება არ არის ტექნიკური ოპტიმიზაციის საკითხი; ეს არის ფუნდამენტური კომპრომისი, რომელიც მოითხოვს გადაწყვეტილების მიღებას იმაზე, თუ რომელი ტიპის შეცდომაა უფრო მისაღები კონკრეტულ სოციალურ კონტექსტში.
მიკერძოების შერბილების სტრატეგიები: წინასწარი, შიდა და შემდგომი ჩარევა
მას შემდეგ, რაც ნათელი ხდება ალგორითმული მიკერძოების არსებობა და მისი გაზომვის სირთულეები, ინჟინერიული ძალისხმევა მიმართულია ამ გადახრების შერბილებისკენ. მიკერძოების შემცირების, ანუ დებიასიზაციის სტრატეგიები ტრადიციულად სამ ძირითად კატეგორიად იყოფა, იმის მიხედვით, თუ მოდელის განვითარების რომელ ეტაპზე ხდება ჩარევა. წინასწარი დამუშავება, ანუ პრე-პროცესინგი, ფოკუსირდება უშუალოდ სატრენინგო მონაცემების მოდიფიკაციაზე მანამ, სანამ ალგორითმი მათთან ურთიერთქმედებას დაიწყებს. ამ ეტაპზე გამოიყენება ისეთი ტექნიკები, როგორიცაა მონაცემთა გადაწონვა, სადაც მარგინალიზებული ჯგუფების წარმომადგენელთა ჩანაწერებს ენიჭება უფრო მაღალი სტატისტიკური წონა, რათა კომპენსირებულ იქნას მათი სიმცირე. ასევე აქტიურად გამოიყენება ხელახალი შერჩევის ანუ რესემპლინგის მეთოდები, რომლებიც ხელოვნურად აბალანსებენ კლასების განაწილებას მონაცემთა ბაზაში. მიზანია შეიქმნას ისეთი სატრენინგო სივრცე, რომელიც თავისუფალია ისტორიული ასიმეტრიებისგან, თუმცა ეს ხშირად იწვევს ორიგინალური მონაცემების ბუნებრივი სტრუქტურის ნაწილობრივ დაკარგვას. ისტორიული მონაცემების მოდიფიკაცია ეთიკურ დილემებსაც წარმოშობს, რადგან ის აჩენს კითხვას, თუ რამდენად გვაქვს უფლება შევცვალოთ ემპირიული წარსული სასურველი მომავლის მოდელირებისთვის.
მეორე და უფრო კომპლექსური სტრატეგია არის შიდა დამუშავება, ანუ ინ-პროცესინგი, რომელიც უშუალოდ მოდელის ტრენინგის ალგორითმში ერევა. ამ დროს ოპტიმიზაციის ფუნქციას ემატება სპეციფიკური შეზღუდვები, რომლებიც მოდელს აიძულებს, დანაკარგის მინიმიზაციასთან ერთად, დააკმაყოფილოს სამართლიანობის წინასწარ განსაზღვრული მეტრიკა. ამ პროცესში ლაგრანჟის მამრავლების ან მსგავსი ოპტიმიზაციის ტექნიკების გამოყენებით, ალგორითმი პოულობს წონასწორობის წერტილს სიზუსტის დანაკარგსა და სამართლიანობის მოგებას შორის. განსაკუთრებული ყურადღების ცენტრშია შეჯიბრებითი დებიასიზაციის ტექნიკა, რომელიც იყენებს გენერაციული შეჯიბრებითი ქსელების მსგავს არქიტექტურას. ამ სცენარში, მთავარი მოდელი ცდილობს შეასრულოს თავისი ძირითადი პრედიქციული ამოცანა, ხოლო პარალელურად მომუშავე მოწინააღმდეგე მოდელი ცდილობს მთავარი მოდელის შიდა რეპრეზენტაციებიდან ამოიცნოს სენსიტიური ატრიბუტები. მთავარი მოდელის მიზანი ხდება ისეთი რეპრეზენტაციების ფორმირება, რომლებიც ინარჩუნებენ პრედიქციულ ძალას, მაგრამ არ შეიცავენ ინფორმაციას დაცული მახასიათებლების შესახებ. ეს მიდგომა საკმაოდ ეფექტურია, თუმცა მნიშვნელოვნად ზრდის გამოთვლით სირთულეს და ტრენინგის არასტაბილურობას.
მესამე მიდგომა, პოსტ-პროცესინგი, გულისხმობს უკვე დატრენინგებული მოდელის გამომავალი შედეგების კორექტირებას. ამ დროს თავად ალგორითმის შიდა პარამეტრები უცვლელი რჩება, მაგრამ ხდება გადაწყვეტილების მიღების ზღურბლების მორგება სხვადასხვა ჯგუფისთვის. მაგალითად, თუ მოდელი სისტემატურად აკნინებს კონკრეტული ჯგუფის შანსებს, ინჟინრებს შეუძლიათ ამ ჯგუფისთვის დაწიონ პოზიტიური კლასიფიკაციის ზღურბლი, რათა მიაღწიონ გათანაბრებულ შანსებს. ეს მიდგომა განსაკუთრებით პრობლემურია იურიდიული თვალსაზრისით, რადგან ის ღიად იყენებს დაცულ მახასიათებლებს განსხვავებული მოპყრობის დასაწესებლად, რაც ბევრ იურისდიქციაში პირდაპირ ეწინააღმდეგება ანტიდისკრიმინაციულ კანონმდებლობას. მიუხედავად იმისა, რომ მიტიგაციის ეს სტრატეგიები ტექნიკურად დახვეწილია, მათ აქვთ ფუნდამენტური შეზღუდვები. ნებისმიერი ფორმის დებიასიზაცია აუცილებლად მოითხოვს კომპრომისს მოდელის საერთო სიზუსტესა და სამართლიანობას შორის. გარდა ამისა, ეს მეთოდები ხშირად განიხილავენ სენსიტიურ მახასიათებლებს როგორც იზოლირებულ ცვლადებს და ვერ უმკლავდებიან იმ ინტერსექციულ უთანასწორობებს, სადაც მიკერძოება წარმოიშობა რამდენიმე იდენტობის კომპლექსური გადაკვეთით.
რატომ ვერ იქნება ალგორითმი სრულად ნეიტრალური?
ტექნიკური მიტიგაციის სტრატეგიების არსებობა ხშირად ქმნის მცდარ მოლოდინს, რომ საკმარისი ინჟინერიული ძალისხმევის პირობებში შესაძლებელია აბსოლუტურად ნეიტრალური და ობიექტური ალგორითმის შექმნა. თუმცა, მანქანური სწავლების ონტოლოგიური ბუნება გამორიცხავს სრულ ნეიტრალობას. უპირველეს ყოვლისა, თავად ოპტიმიზაციის პროცესი არის ღირებულებებით დატვირთული აქტი. როდესაც დეველოპერი ირჩევს ობიექტურ ფუნქციას, ის იღებს ნორმატიულ გადაწყვეტილებას იმის შესახებ, თუ რა არის სისტემისთვის სასურველი. გადაწყვეტილება, მოხდეს სისტემის ოპტიმიზაცია მაქსიმალური მოგების, ჩართულობის თუ რისკების მინიმიზაციის მიმართულებით, პირდაპირ განსაზღვრავს მოდელის ქცევას. ამიტომ, ალგორითმი ყოველთვის წარმოადგენს მისი შემქმნელების ინსტიტუციური პრიორიტეტებისა და ეკონომიკური მიზნების მათემატიკურ ექსტენციას.
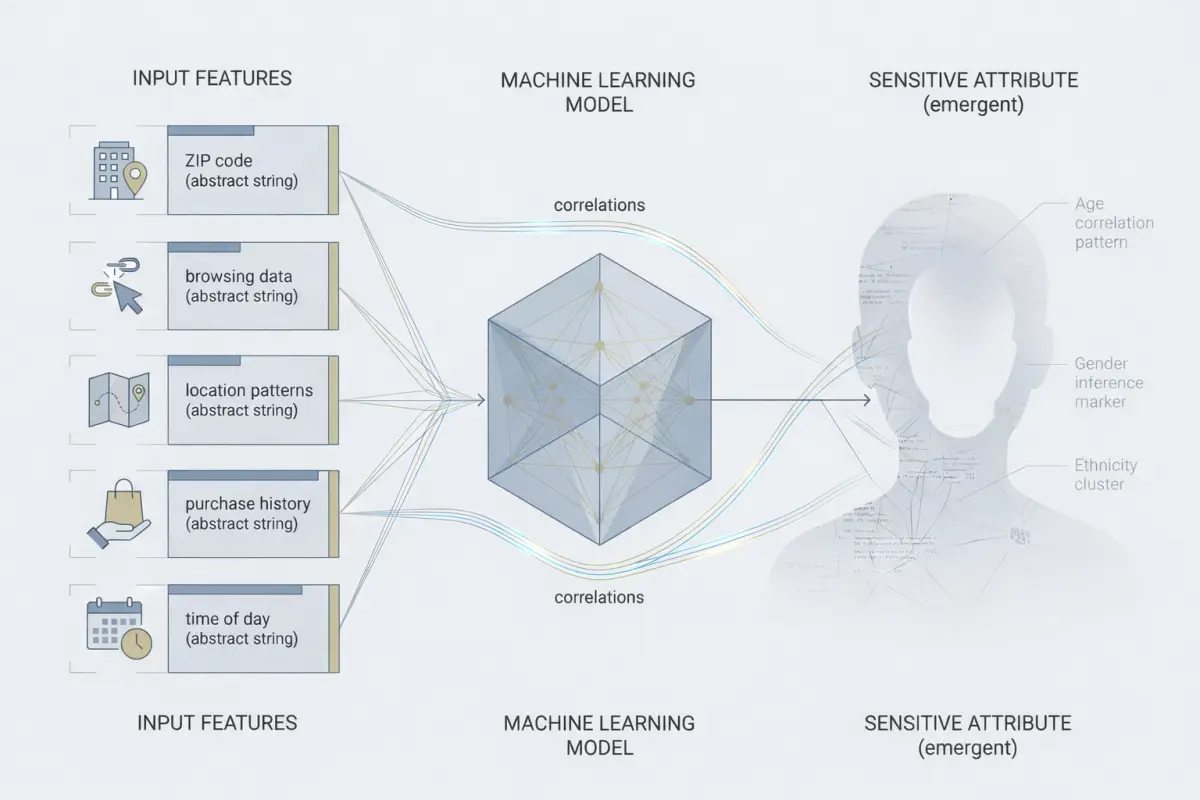
უფრო მეტიც, ლატენტური მიკერძოების ფენომენი აჩვენებს, რომ მოდელიდან სენსიტიური ცვლადების ამოღება არ არის საკმარისი ნეიტრალობის მისაღწევად. მაღალგანზომილებიან მონაცემთა სივრცეში თითქმის ნებისმიერი უწყინარი მახასიათებელი შეიძლება იქცეს აკრძალული კატეგორიის პროქსი ცვლადად. საცხოვრებელი ადგილის საფოსტო ინდექსი, მუსიკალური გემოვნება ან ბრაუზერის ისტორია შეიცავს კოდირებულ ინფორმაციას ადამიანის სოციალურ-ეკონომიკური სტატუსის, ეთნიკური წარმომავლობისა თუ გენდერის შესახებ. მანქანური სწავლების მოდელები არსებითად კორელაციური ძრავებია, რომლებიც მოკლებულნი არიან მიზეზ-შედეგობრივი კავშირების გააზრების უნარს. შესაბამისად, ისინი ითვისებენ სოციალური უთანასწორობის ყველა იმ სტრუქტურულ კვალს, რომელიც მონაცემთა მატრიცაშია აღბეჭდილი. ღრმა ნეირონული ქსელები, თავიანთი უნარით იპოვონ ფარული კორელაციები, აუცილებლად აღმოაჩენენ და გამოიყენებენ ამ ლატენტურ სტრუქტურებს, თუ ისინი ეხმარება მოდელს დანაკარგის ფუნქციის მინიმიზაციაში. შედეგად, მიკერძოება ხდება არა ზედაპირული ატრიბუტი, არამედ სისტემის შიდა რეპრეზენტაციებში ღრმად ჩაქსოვილი თვისება.
ნეიტრალობის ილუზიას კიდევ უფრო არყევს დანერგვის კონტექსტზე დამოკიდებულების ფაქტორი. ალგორითმი, რომელიც ავლენს სამართლიანობის მაღალ ხარისხს ერთ კონკრეტულ სოციალურ ან გეოგრაფიულ გარემოში, სრულიად შესაძლებელია გახდეს დისკრიმინაციული ინსტრუმენტი სხვა კონტექსტში გადატანისას. მონაცემთა ისტორიული პატერნები, ადამიანთა ქცევის ნორმები და ინსტიტუციური სტრუქტურები სივრცესა და დროში ცვალებადია. როდესაც ალგორითმი ინტეგრირებულია ახალ სოციალურ-ტექნიკურ ეკოსისტემაში, მისი პროგნოზები კარგავენ კალიბრაციას ახალ რეალობასთან. ალგორითმული ნეიტრალობა არ არის სტატიკური თვისება; ის არის დინამიკური მდგომარეობა, რომელიც იცვლება გარემოსთან ურთიერთქმედების პროცესში. სოციალურ-ტექნიკური პერსპექტივა გვკარნახობს, რომ მოდელი და საზოგადოება თანა-კონსტრუირდებიან, რაც საბოლოოდ გამორიცხავს ალგორითმის, როგორც დამოუკიდებელი დამკვირვებლის პოზიციას.
სისტემური შეჯამება
ალგორითმული მიკერძოების კომპლექსური ანალიზი ნათლად აჩვენებს, რომ ხელოვნური ინტელექტის სისტემებში არსებული უთანასწორობა არ წარმოადგენს უბრალო პროგრამულ ხარვეზს, რომლის აღმოფხვრაც სტანდარტული დებაგინგის პროცედურებით არის შესაძლებელი. როგორც მონაცემთა განაწილების ასიმეტრიის, ოპტიმიზაციის ფუნქციების მათემატიკური სიბრმავისა და უკუკავშირის მარყუჟების კვლევამ, ასევე სამართლიანობის მეტრიკებს შორის არსებულმა შეუძლებლობის თეორემებმა დაადასტურა, მიკერძოება სისტემის არქიტექტურული და სტრუქტურული თვისებაა. მიტიგაციის სტრატეგიების თანმდევი კომპრომისები მიუთითებს იმაზე, რომ წმინდა ტექნოლოგიური ჩარევები ყოველთვის შეზღუდული იქნება მათი ეფექტურობით. ალგორითმები ასრულებენ ისტორიული მონაცემების ექსტრაპოლაციას და მოქმედებენ როგორც საზოგადოებაში უკვე არსებული ძალაუფლებრივი სტრუქტურებისა და სტატისტიკური უთანასწორობების გამაძლიერებლები. ნეიტრალობის ილუზიის მსხვრევა მოითხოვს პარადიგმულ ცვლილებას ხელოვნური ინტელექტის განვითარებაში, სადაც მოდელის შეფასება გასცდება მხოლოდ სიზუსტის საზომებს და მოიცავს სოციალურ-ტექნიკური ზეგავლენის უწყვეტ, კონტექსტუალურ ანალიზს. მხოლოდ ამ მრავალშრიანი სირთულის აღიარებით ხდება შესაძლებელი ისეთი სისტემების დაპროექტება, რომლებიც შეძლებენ მინიმუმამდე დაიყვანონ სტრუქტურული ზიანი და უზრუნველყონ უფრო გამჭვირვალე, ეთიკურად გააზრებული ალგორითმული მმართველობა.
კომენტარები (0)
ამ ავტორისგან
აირჩიე კრიპტო და დაეხმარე ავტორს 💫
×TXintEE7aezp6QxNNtbghCXvmXJdgofEyr
0x9c6299454A6B617A0Db228024279F2a3EEf956dD
bc1qj7caz3xfh5qd4ud3v3nh7k4tfl5lg8jh9er73e
0x9c6299454A6B617A0Db228024279F2a3EEf956dD
3TndfWAhPytTaBZjC2GbNWqh9iWx171SYACjbG2j5vx8
DHsrtwiL56Xk1xAj3fe8pVcfLhE8xgt3EQ
0x9c6299454A6B617A0Db228024279F2a3EEf956dD
UQDFkubJxb8KmxFmy1arJxkewzmNEg6-G2pJFVzFihB65d7W
ltc1q3fentl6ur9cxm0vxyqkdmmzxkj92j00p9l8m7z
✍ სტატიის ავტორი
- რეგისტრაცია: 3 მაისი 2025, 16:22
- მდებარეობა: საქართველო, ქუთაისი